FODOMUST
FoDoMuST: Fouille de données Multi-Stratégie Multi-Temporelles
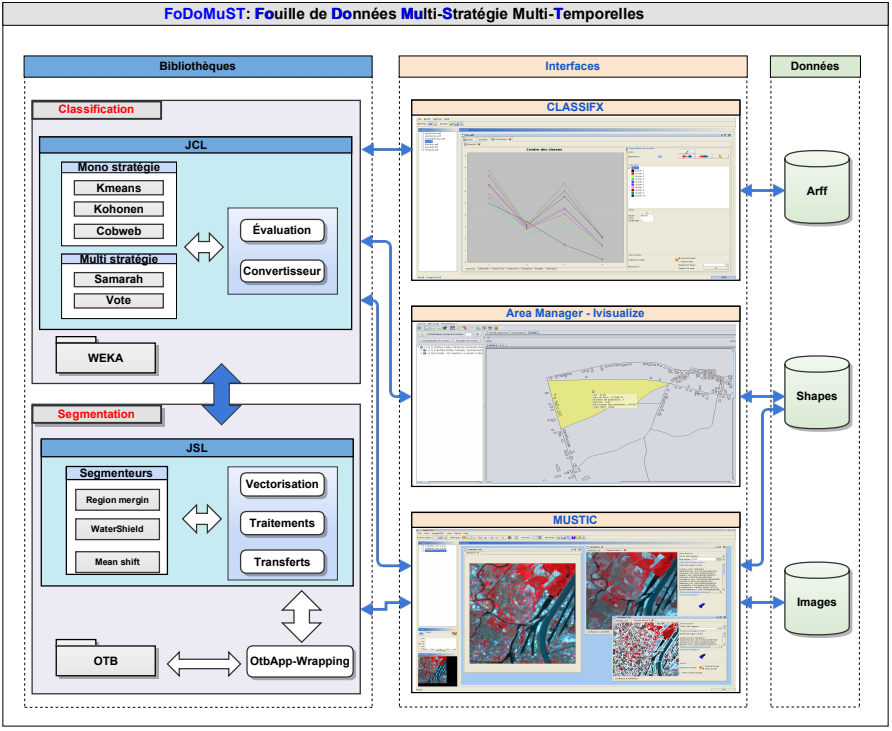
La plateforme FODOMUST est une implantation concrète des méthodes, librairies et interfaces dédiées au clustering de données complexes proposées au sein d’ICube. Elle intègre une version multisource de la méthode de clustering collaboratif multistratégie SAMARAH. Sa principale originalité est qu’elle offre à l’utilisateur les méthodes et les interfaces permettant le clustering sous contraintes incrémental de données temporelles symboliques ou numériques. L’interface MULTICUBE dédiée à l’analyse de séries temporelles offre aussi un accès à un ensemble d’algorithmes de segmentation soit propres à ICUBE soit faisant appel à l’OTB diffusée par le CNES.
Trois interfaces - Deux bibliothèques
Démo Video FoDoMuST
MultiCube
L'interface MultiCube est une extension de Classifx (voir ci-dessous).
MultICube (Multi-Strategy Multi-Resolution Multi-Temporal Image Classification) est une interface permettant la classification d'images de télédétection par des approches pixels et orientées objets.
Elle permet de :
- charger/modifier/sauvegarder des images via Orfeo Tool Box (CNES),
- classifier (clustering uniquement) des images (par pixels ou basée régions) via la bibliothèque JCL,
- segmenter de telles images via la bibliothèque JSL.
Téléchargement et exécution de MultICube (Version Février 2019)
Lancement de MultICube (Linux et Windows)
Il faut impérativement exécuter soit launcher.sh (Linux) ou launcher.bat (Win-dows).
Cela permet d’associer les bonnes librairies. Si vous utiliser uniquement java -jar , MultICube ne peut pas charger les image : il tourne donc éternellement et rien ne se passe lors de l'ouverture d'images.
Attention : Il faut lancer le script dans l'invite de commande depuis le dossier d'installation. (Sera changé dans les prochaines versions de l’installeur).
Windows
Quelques remarques :
- Installer MultiCube dans le dossier Users (Documents par exemple) pour des questions de droits (ou alors il faut lancer l'invite de commande en administrateur).
- Si ça ne fonctionne pas, il faut vérifier que Java 64b est bien installé. En effet, il semblerait que Oracle télécharge la version 32b par défaut même si on est sur une installe 64b. Dans ce cas il faut clicker sur le lien suivant (voir screenshot ci-dessous) puis prendre la version 64b (l'installation demandera d'enlever l’ancienne version 32b). https://seafile.unistra.fr/f/fc79617f8dec4dd3a950/?dl=1
| Télécharger MultICube pour Linux 64 bits (zip) |
| Télécharger MultICube pour Windows 64bits (zip) |
| Télécharger MultICube pour Windows 34bits (zip) |
Autres interfaces
L'interface Classifx
L'interface Classifx concrétise toutes nos activités de recherche sur la fouille de données collaborative multistratégie et sur la pondération d'attributs.
Elle permet de :
- charger/modifier/sauvegarder des données ARFF (Attribute-Relation File Format),
- classifier (clustering uniquement) des données ARFF via la bibliothèque JCL.
L'interface Area manager
- Area manager est une solution logicielle regroupant deux logiciels complémentaires : GeOpenSim et Ivisualize.
GeOpenSim, acronyme de Géographique Open Source De Simulation, est un logiciel permettant l' analyse des tissus urbains, en simulant en fonction du temps les évolutions d'une zone urbaine, autant sur le plan de l'expansion que la densification de son ensemble, afin d'analyser les impacts possibles d'une décision de développement urbain sur cette zone. GeOpenSim permet, à partir de données Shapefiles issues de BD Topo type IGN, de créer des îlots urbains, de les classifier en utilisant un arbre de décision et de créer des séquences temporelles correspondant à leurs évolutions.
- iVisualize est une interface permettant la visualisation, la classification supervisée ou non de séquences d'évolution temporelle d’îlots créés par GeOpenSim. Il est basé sur DTW, JCL, et une matrice de similarité donnée par l'expert. Les résultats obtenus peuvent être exportés sous forme graphique (dendrogramme), image, PDF, ou encore Shapefiles.
Java Clustering Library
Nos premiers travaux ont été écrits en C++ et traduits en Java en 2000 pour obtenir la bibliothèque JCL (Java Clustering Library). Si initialement cette bibliothèque ne contenait que les classifieurs classiques, les classifieurs proposés dans nos recherches y ont été intégrés au fur et à mesure de leur définition.
Actuellement, elle regroupe un ensemble des classifieurs classiques (Kmeans, Cobweb, …), la méthode de classification multi-stratégie SAMARAH et les méthodes génétiques dont Maclaw.
A partir de 2003, cette bibliothèque permet la classification de données au format ARFF et celle d'iimages de télédétection.
Java Segmentation Library
Cette bibliothèque date de 2012. Elle regroupe tous les algorithmes de segmentation proposés par l'équipe. Elle permet aussi d'utiliser une part importante de algorithmes intégrés dans l'OTB.
Documents
Vous trouverez aussi un rapport de stage décrivant les grandes lignes de l'interface MUSTIC ainsi qu'une description rapide de SAMARAH : Media:Documents.zip
Contacts
Pour tout renseignement sur les méthodes liées à Mustic et JCL et pour obtenir les sources Cliquez ici
Ground Truth Agreement Toolbox (GTAT)
This Matlab toolbox accompanies the paper:
- T. Lampert, A. Stumpf, and P. Gancarski, 'An Empirical Study into Annotator Agreement, Ground Truth Estimation, and Algorithm Evaluation'. (submitted).
It contains implementations of the functions described within the paper related to agreement analysis and the evaluation of detectors using different ground truth estimation techniques. It may also be used to recreate the figures for the fissure case study to gain a better understanding of the method (see the QUICK START section of the included readme file).
It is assumed that you have a number of annotations related to the same image.
To use the toolbox's functions, simply add the toolbox directory to Matlab's path. Within the header of each function may be found a short description of its purpose and in which section of the paper its mathematical derivation can be found. For more information see the toolbox's README file.
The toolbox is separated into three main functions:
- The agreement_analysis function calculates the statistics outlined in our paper for the collection of annotations passed to it.
- The calculate_GTs function calculates ground truths using the methods outlined below:
- the LSML algorithm;
- the agreement of any annotator;
- the agreement of 50% of annotators;
- the agreement of 75% of annotators;
- the STAPLE algorithm;
- by excluding outliers of the annotator clustering evaluation;
- and by excluding outliers and then calculating the 50% agreement level.
- The detector_analysis function determines the detector's performance respective to each of the ground truths passed to the function, it then ranks the detectors based upon these performances.
The toolbox can be downloaded here.
Precision-Recall Toolbox (PRT)
This Matlab toolbox accompanies the paper:
- T. Lampert and P. Gancarski, 'The Bane of Skew: Uncertain Ranks and Unrepresentative Precision'. Machine Learning, pp. (submitted), 2013.
It contains implementations of the functions described within the paper to calculate Precision-Recall, temporal Precision-Recall, integrated Precision-Recall and weighted Precision-Recall curves given a classifier's response and a corresponding ground truth. It may also be used to recreate the paper's figures to gain a better understanding of the method.
To use the toolbox's functions, simply add the toolbox directory to Matlab's path. Within the header of each function may be found a short description of its purpose and in which section of the paper its mathematical derivation can be found. For more information see the toolbox's README file.
The toolbox can be downloaded here.
La plate-forme bioinformatique BISTRO
La plate-forme bioinformatique de Strasbourg BISTRO a été reconnue par l’Institut Français de Bioinformatique comme membre du réseau national des plateformes bioinformatiques (RéNaBi) Nord-Est qui inclut, outre Strasbourg, Lille, Vandoeuvre les Nancy et Reims en accord avec la politique de l’IFB et de RéNaBi d’améliorer la visibilité nationale et internationale des réalisations bioinformatiques françaises en aggrégeant des plateformes de sites multidisciplinaires et multi-instituts. Dans ce cadre, BISTRO réunit sur Strasbourg des équipes IGBMC, IBMC, IBMP, GMGM, IPHC, ICube et est à même de fournir un ensemble bioinformatique cohérent incluant : expertise, outils et ressources, algorithmes d'exploration de données. Ces ressources sont axées sur les analyses évolutives et fonctionnelles dans divers domaines d'application, y compris les études biomédicales, les plantes, les levures et bactéries.